Building apps with AI and Large Language Models can get expensive quickly, and the culprit might surprise you — it's often the way your data is formatted.
Each curly brace, square bracket, and quotation mark in JSON gets counted as a token when you send data to an LLM.
If you're dealing with large datasets or complex structures, those tokens add up fast, burning through your budget in no time.
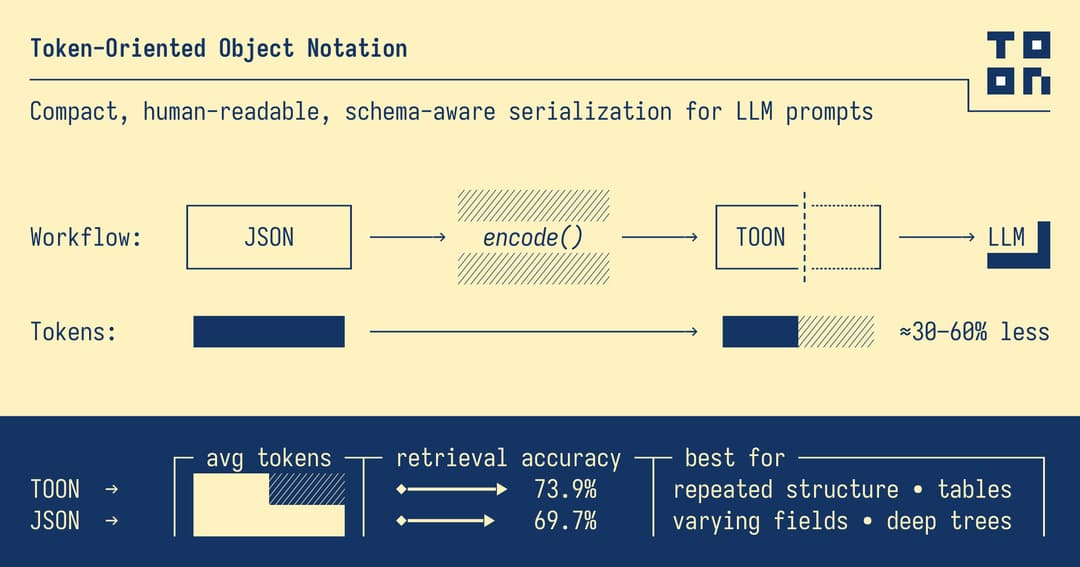
This is where TOON (Token-Oriented Object Notation) comes to the rescue — a data format built from the ground up to work efficiently with LLMs while staying easy to read and understand.
Understanding TOON
TOON stands for Token-Oriented Object Notation — a streamlined data format made for the AI era.
Here's the simple way to think about it:
"It's like JSON got a makeover for the age of language models."
TOON removes unnecessary symbols like curly braces, square brackets, and quotation marks. Instead, it uses smart indentation and table-style patterns.
What you get is data that both humans and AI models can read without trouble, using way fewer tokens in the process.
The Problem TOON Solves
Every time you send JSON data to an LLM:
- Each punctuation symbol increases your token count
- When you have long lists with repeating field names, the cost multiplies
- All that extra formatting doesn't actually help the model understand better
TOON solves these issues by:
- Writing field names just once for each table-style block
- Using indentation instead of commas and braces
- Keeping your data clear while removing unnecessary symbols
You'll usually use 30–60% fewer tokens.
See TOON in Action
JSON Version
{
"employees": [
{ "id": 1, "name": "Sarah" },
{ "id": 2, "name": "Marcus" }
]
}
TOON Version
employees[2]{id,name}:
1,Sarah
2,Marcus
The data structure stays the same. The information remains unchanged. But you're using about half the tokens.
Working with TOON
You can use the official TOON packages for both JavaScript/TypeScript and Python.
JavaScript/TypeScript
Getting Started
npm install @toon-format/toon
Sample Code
import { encode, decode } from "@toon-format/toon";
const data = {
members: [
{ id: 1, name: "Elena", position: "manager" },
{ id: 2, name: "David", position: "developer" },
],
};
// Encode to the TOON format
const toon = encode(data);
console.log("TOON Format:\n", toon);
// Decode back to JSON
const parsed = decode(toon);
console.log("Decoded JSON:\n", parsed);
Python
Getting Started
pip install git+https://github.com/toon-format/toon-python.git
Sample Code
from toon_format import encode, decode
data = {
"members": [
{"id": 1, "name": "Elena", "position": "manager"},
{"id": 2, "name": "David", "position": "developer"},
]
}
toon = encode(data)
print("TOON Format:\n", toon)
# Decode back to JSON if needed
parsed = decode(toon)
print("Decoded JSON:\n", parsed)
What You'll See (Both Languages)
TOON Format:
members[2]{id,name,position}:
1,Elena,manager
2,David,developer
Decoded JSON:
{
members: [
{ id: 1, name: 'Elena', position: 'manager' },
{ id: 2, name: 'David', position: 'developer' }
]
}
When to Use?
TOON works best with flat, table-like JSON data. Deep nesting is not its strong suit. When data has many nested levels, the indentation and extra context can actually use more tokens than JSON.
Example of poor fit:
{
"organization": {
"divisions": [
{
"name": "Operations",
"staff": [{ "id": 1, "name": "Patricia" }]
}
]
}
}
- This kind of structure might become longer in TOON, not shorter.
Perfect for:
- Simple lists (no nested structure)
- Prompt templates
- Training or testing datasets for models
Skip it for:
- Complex nested structures
- Data with many relationship levels
Quick Summary
TOON (Token-Oriented Object Notation) offers a smart, token-saving alternative to JSON for AI and LLM projects.
✅ It provides a simpler format.
✅ It is easy to read.
✅ It saves up to 60% on tokens.
For LLM pipelines, prompt templates, or structured AI datasets, TOON helps you save tokens, cut costs, and keep your data organized.
Test Token Savings Yourself
You can measure token savings between JSON and TOON. Here's how to do it in both JavaScript and Python using OpenAI's tiktoken tokenizer.
JavaScript/TypeScript
Set Up Your Tools
npm install @toon-format/toon tiktoken
The Script
import { encode } from "@toon-format/toon";
import { encoding_for_model } from "tiktoken";
const data = {
team: [
{ id: 1, name: "Rachel", department: "finance" },
{ id: 2, name: "Tom", department: "marketing" },
{ id: 3, name: "Olivia", department: "design" },
{ id: 4, name: "James", department: "engineering" },
{ id: 5, name: "Sofia", department: "operations" },
{ id: 6, name: "Kevin", department: "sales" },
{ id: 7, name: "Emma", department: "hr" },
{ id: 8, name: "Lucas", department: "product" },
],
};
const jsonData = JSON.stringify(data, null, 2);
const toonData = encode(data);
const tokenizer = encoding_for_model("gpt-4o-mini");
const jsonTokens = tokenizer.encode(jsonData).length;
const toonTokens = tokenizer.encode(toonData).length;
console.log("JSON tokens:", jsonTokens);
console.log("TOON tokens:", toonTokens);
tokenizer.free();
Python
Set Up Your Tools
pip install git+https://github.com/toon-format/toon-python.git tiktoken
The Script
import json
import tiktoken
from toon_format import encode
data = {
"team": [
{"id": 1, "name": "Rachel", "department": "finance"},
{"id": 2, "name": "Tom", "department": "marketing"},
{"id": 3, "name": "Olivia", "department": "design"},
{"id": 4, "name": "James", "department": "engineering"},
{"id": 5, "name": "Sofia", "department": "operations"},
{"id": 6, "name": "Kevin", "department": "sales"},
{"id": 7, "name": "Emma", "department": "hr"},
{"id": 8, "name": "Lucas", "department": "product"},
]
}
json_data = json.dumps(data, indent=2)
toon_data = encode(data)
tokenizer = tiktoken.encoding_for_model("gpt-4o-mini")
json_tokens = len(tokenizer.encode(json_data))
toon_tokens = len(tokenizer.encode(toon_data))
print(f"JSON tokens: {json_tokens}")
print(f"TOON tokens: {toon_tokens}")
Sample Results (Both Languages)
JSON tokens: 211
TOON tokens: 74
Conclusion
If you're sending lots of data to LLMs, TOON can make a real difference in your costs. It won't work for every situation — deeply nested data should still use JSON. But for simple lists and tables, switching to TOON is like getting a discount on every API call you make.